Preface
D5 Render a déployé une nouvelle fonctionnalité « D5 SR Image Rendering » dans la dernière version 2.5. « SR » signifie « Super Resolution », une technologie développée en interne par un D5 qui transforme les images basse résolution en images haute résolution.
Basé sur un algorithme de génération d'images à super-résolution par réseau neuronal, le D5 SR est associé à des cartes de caractéristiques de rendu multicanaux pour accélérer considérablement le rendu des images.
La technologie Super Resolution peut être utilisée dans un large éventail d'applications. Par exemple, il peut améliorer les détails et la résolution du rendu vidéo, et dans le rendu en temps réel, il peut augmenter la fréquence des images pour améliorer l'expérience utilisateur.
Mais soyons honnêtes, il a toujours été difficile d'amplifier la résolution des images rendues sans distorsion.
Les points forts de la D5 SR
Une reconstruction plus réaliste
Real-ESGRAN est un algorithme de super-résolution aveugle qui n'a pas été spécifiquement entraîné pour les images de rendu D5. Par conséquent, lorsque vous doublez la résolution des images rendues, real-esrgan peut présenter des artefacts évidents tels que des matériaux non naturels.
Pourtant, ce problème est bien résolu avec le D5 SR, comme vous pouvez le voir sur les images de test suivantes. En effet, le D5 SR a ajouté la géométrie, le matériau, la texture et d'autres informations de cet objet afin d'améliorer la qualité des images haute résolution reconstruites.

Zoomez pour vérifier les détails. Vous pouvez constater que l'algorithme SR sans entraînement entraîne de graves distorsions telles que des flous, des bavures ou des textures anormales, alors que ce n'est pas le cas du D5 SR.
Optimisé Reflexions
Lors du premier test du D5 SR, les images deux fois étendues ont perdu certains détails de réflexion.
Après avoir importé les informations sur les canaux de réflexion et les matériaux, le D5 SR peut mieux reproduire les reflets.
Vous pouvez voir la différence dans ces deux scènes.

Améliorative Rendu Efficacité
Après avoir activé le D5 SR, vous constaterez une vitesse de rendu accrue pour les images en haute résolution.
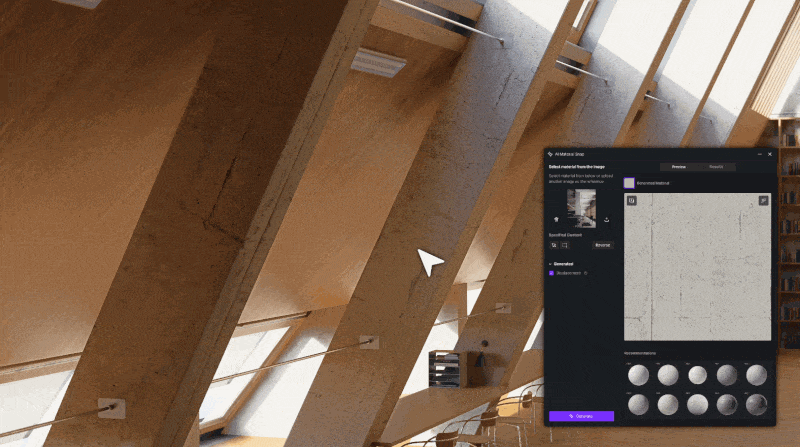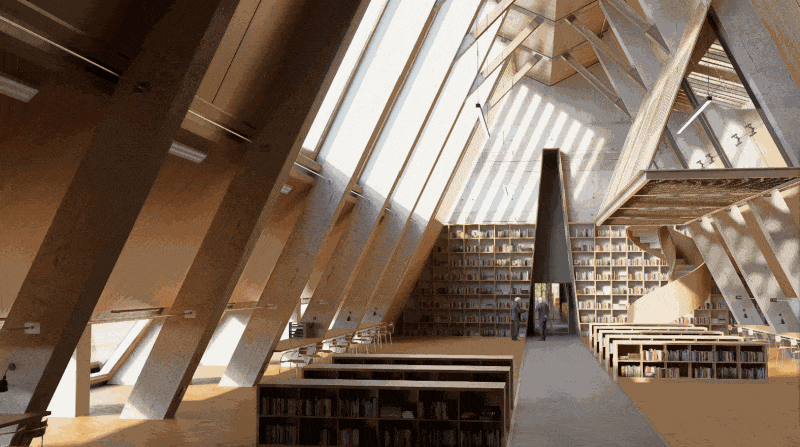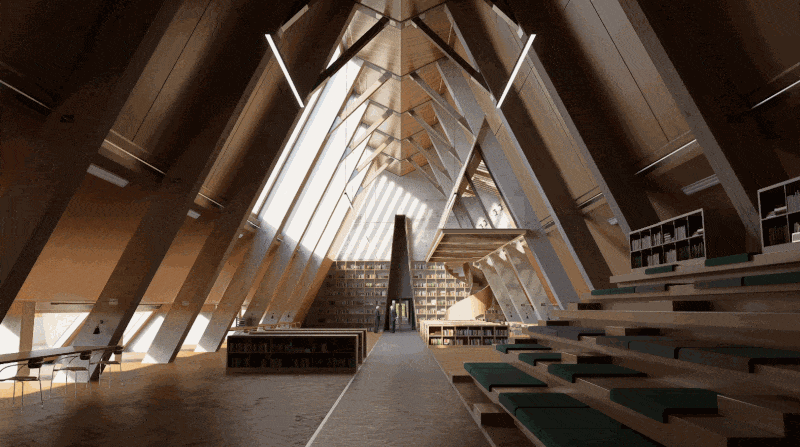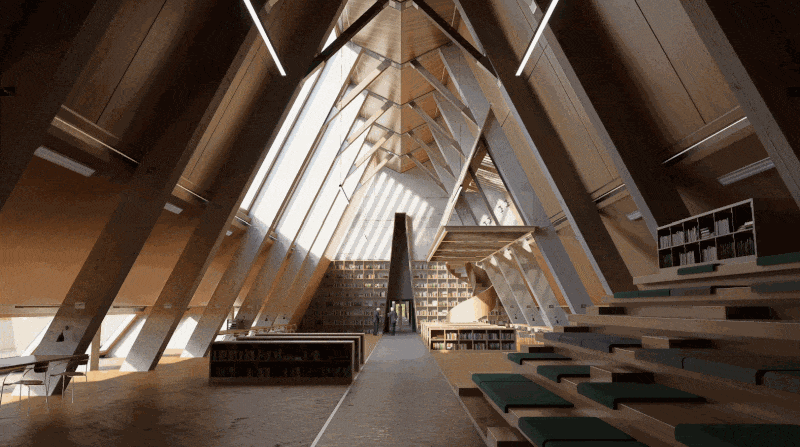
Pris this scene as example.
Pour le rendu d'une image en résolution 16K (15360 x 8640), il vous faudra 1h17m13 s lorsque le D5 SR est éteint et seulement 27 m23 s après l'avoir allumé, ce qui permet d'économiser 65 % du temps total.


Comment utiliser le D5 SR
Accédez à Menu > Préférences > Widget et activez « D5 SR Image Rendering beta ». Il fonctionne automatiquement lorsque D5 affiche des images sans avoir besoin d'autres paramètres.
Veuillez noter que l'algorithme D5 SR est activé uniquement sur les images dont la taille est supérieure à une résolution de 1440 x 1440.

Comment est né le D5 SR
L'équipe D5 entraîne l'algorithme SR à partir d'une vaste collection d'images générées par D5. Le réseau neuronal peut utiliser efficacement les informations préalables tirées de ces données d'entraînement pour nous offrir une meilleure reconstruction en haute résolution.
Cependant, au début, nous ne disposons pas de suffisamment d'informations sur les scènes 3D telles que la géométrie, les matériaux et les textures, ce qui a entraîné un écart entre les résultats de la reconstruction et le rendu physique. Par conséquent, nous avons introduit ces informations 3D en tant que caractéristiques d'entrée pour obtenir un meilleur résultat.
Techniquement, l'équipe de R & D du D5 a réalisé les opérations suivantes :
Tout d'abord, nous utilisons l'albédo à haute résolution et les informations normales pour reconstruire la texture et les caractéristiques géométriques.
Nous intégrons ensuite des informations sur la réflexion, la transparence, le métal et la rugosité pour optimiser les effets de réflexion et de surbrillance.
Pour améliorer encore le résultat de la reconstruction, nous avons utilisé un nouvel algorithme. Il améliore le réseau neuronal ESRGAN d'origine et utilise un réseau à double flux pour traiter respectivement des images originales en basse résolution et des graphiques d'informations de canal en haute résolution. Nous avons utilisé la perte L1 relative pour améliorer la supervision des erreurs de pixels et de la perte de perception, et avons introduit une perte contradictoire pour améliorer le résultat de super-résolution.
Enfin, nous avons utilisé une structure de réseau en forme de U pour remplacer certains blocs denses résiduels dans l'ESRGAN, afin d'élargir la plage du champ de détection de l'extraction des caractéristiques des cartes d'informations des canaux haute résolution et d'améliorer encore la vitesse d'inférence.




.png)

















.png)
1%20(2).png)





















%20(1).png)
.png)

.png)






































.png)